TABLE/DATA 추가 및 설정
department 테이블에 기본키(primary key) 설정
alter table department add primary key(dept_id);
신규 테이블 student 설정
- 기본키 : stu_id (학번),
- 외래키 : dept_id (학과아이디) – department 테이블의 기본키와 연결
create table student (
stu_id varchar(10) primary key,
name varchar(10) not null,
address varchar(10),
point int,
dept_id varchar(10),
foreign key(dept_id) references department(dept_id)
);
DATA 무결성 확인
참조무결성 확인
DELETE FROM department WHERE dept_id='G31';
- 실행결과 : 에러 발생 (삭제 불가)
- student 테이블에서 department테이블의 dept_id를 외래키로 참조하고 있기 때문에 임의로 삭제하는 것이 불가능함 (참조무결성 위반)
서브 쿼리(Sub Query)
쿼리문 안에 또 쿼리문이 들어있는 것
SELECT * FROM student
WHERE
dept_id = (SELECT dept_id FROM dept WHERE office='2nd floor');
만약 서브 쿼리의 결과가 둘 이상이 되면 에러 발생➡IN 사용
SELECT * FROM student
WHERE
dept_id IN (SELECT dept_id FROM dept WHERE office='2nd floor');
DML – 집계함수
통계연산 기능 제공
예:어떤반의학생수는? 학급별평균성적은?가장성적이높은학생은?
종류
- count : 데이터의 개수를 구한다.
- sum : 데이터의 합을 구한다.
- avg : 데이터의 평균 값을 구한다.
- max : 데이터의 최대 값을 구한다.
- min : 데이터의 최소 값을 구한다.
sum, avg는 숫자형 데이터 타입을 갖는 필드에서만 적용 가능
count
count(<필드이름>)
count(distinct <필드이름>)
- 해당 필드에 값이 몇 개인지 출력
- distinct: 서로 구별되는 값의 개수가 필요한 경우에만 사용
- NULL은 계산에서 제외됨
- <필드이름>에 필드 이름 대신 '*'가 사용된 경우에는 레코드의 개수를 계산
예1> student 테이블의 전체 학생 수 출력
SELECT count(*) FROM student;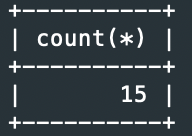
예2> student 테이블의 address 필드의 수 출력
SELECT count(address) FROM student;
SELECT count(distinct address) FROM student; // 중복제거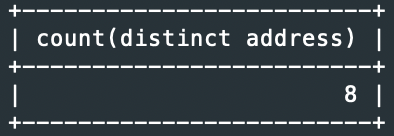
예3> student 테이블에서 dept_id 값이 G31 인 학생 수 출력
SELECT count(*) FROM student WHERE dept_id='G31';
sum
sum(<필드이름>)
- 해당 필드 값의 합 출력
예1> student 테이블의 H31 학급 학생의 point 총 합
SELECT sum(point) FROM student WHERE dept_id='H31';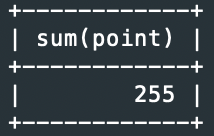
avg
avg(<필드이름>)
- 해당 필드의 평균값 출력
예1> 전체 학생의 point 평균
SELECT avg(point) FROM student;
length
length(<필드이름>) 또는 length(‘문자열‘)
- 해당 필드의 길이 또는 해당 문자열의 길이를 반환
예1> department 테이블의 dept_name 칼럼의 길이
SELECT length(dept_name) FROM department;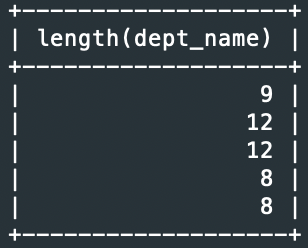
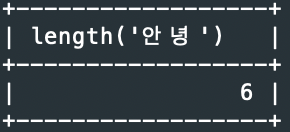
예2> ‘안녕’ 문자열의 길이(byte)
SELECT length(‘안녕’);
글자(한글 포함) 수를 알고 싶다면 CHAR_LENGTH 함수를 사용

CONCAT
CONCAT(‘문자열1’, ‘문자열2’, ‘문자열3’ ...);
- 전달받은 문자열을 모두 결합하여 하나의 문자열로 반환
- 전달받은 문자열 중 하나라도 NULL이 존재하면 NULL을 반환
예1> 문자열 3개를 연결하여 반환
SELECT CONCAT(‘Hello ’, ‘My’, ‘SQL’);
RIGHT, LEFT
RIGHT(‘문자열’, N) / LEFT(‘문자열’, N)
- RIGHT : 문자열의 오른쪽부터 N개 문자열 반환
- LEFT : 문자열의 왼쪽부터 N개 문자열 반환
예1> 문자열의 오른쪽 3개 반환
SELECT RIGHT(‘Hello MySQL’, 3);
LOWER, UPPER
LOWER(‘문자열’) / UPPER(‘문자열’)
- LOWER : 문자열의 문자를 모두 소문자로 변경
- UPPER : 문자열의 문자를 모두 대문자로 변경
예1> 해당 문자열을 모두 소문자로
SELECT LOWER(‘Hello MySQL’);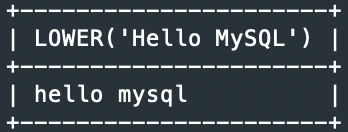
REPLACE
REPLACE(‘문자열1’, ‘특정 문자열‘, ‘바꾸고 싶은 문자열')
- 문자열1에 포함된 ‘특정 문자열'을 ‘바꾸고 싶은 문자열'로 교체
예1> MS를 My로 변경
SELECT REPLACE(‘MS SQL’, ‘MS’, ‘My’);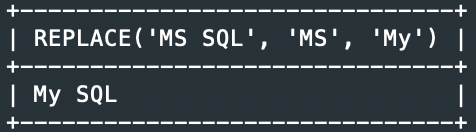
GROUP BY
GROUP BY <필드리스트>
- GROUP BY 에 지정된 필드의 값이 같은 레코드끼리 그룹을 지어 각 그룹별로 집계함수 적용
예1> 학생 주소(지역)별 학생 수 출력
SELECT address, count(stu_id) FROM student GROUP by address;
LIMIT
LIMIT <숫자> 또는 LIMIT <숫자1, 숫자2>
- 출력 개수를 제한
- LIMIT <N> : 상위의 N개만 출력
- LIMIT <N1, N2> : N1번째 레코드 이후(N1+1번째)부터 N2개의 레코드 출력
예1> department 테이블에서 상위 3개의 레코드만 출력
SELECT * FROM department LIMIT 3;
예2> department 테이블에서 3번째 레코드 이후부터 2개의 레코드만 출력
SELECT * FROM department LIMIT 3, 2;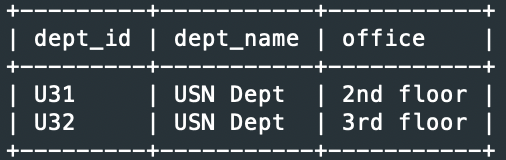
'T자형 개발 > Database' 카테고리의 다른 글
| SQL null일 경우 대체어 표시 (0) | 2022.02.19 |
|---|---|
| SQL HAVING (0) | 2022.02.19 |
| SQL의 구성: DML 데이터 검색(SELECT) (0) | 2021.05.23 |
| SQL의 구성: DML 데이터 수정(UPDATE), 삭제(DELETE) (0) | 2021.05.23 |
| SQL의 구성: DML 레코드 삽입(INSERT) (0) | 2021.05.08 |
'T자형 개발/Database'의 다른글
- 현재글기본키 참조와 서브 쿼리와 DML - 집계함수